|
Xi Xiao Hi👋 I'm Xi Xiao, a third-year Ph.D. student in Computer Science at the University of Alabama at Birmingham, cd-advised by Prof. Tianyang Wang and Prof. Min Xu from Carnegie Mellon University. I'm also a student researcher at Oak Ridge National Laboratory working with Dr. Xiao Wang since May 2025. I am a core contributor to ORBIT-2, an exascale climate foundation model trained on the Frontier supercomputer. The work received the Best Paper Award at SC 2025 and is a ACM Gordon Bell Prize finalist. ORBIT-2 has since been integrated into NVIDIA’s enterprise climate AI stack, powering large-scale forecasting services that reach millions of users worldwide. I am currently seeking a Summer 2026 internship focused on LLMs / MLLMs post-training stage research and applications, please feel free to connect me if my experience match your team:) |

|
News
|
ResearchI have broad interests in computer vision, and language models. My recent work focuses on the post-training stage of large-scale models (LLMs/MLLMs/LVMs), including parameter-efficient fine-tuning (PEFT), reinforcement learning–based alignment, and model quantization. I aim to build efficient and robust intelligent systems that can perform reliably in extreme scenarios with limited data, limited compute, and limited storage resources. Some representative papers are highlighted. |
|
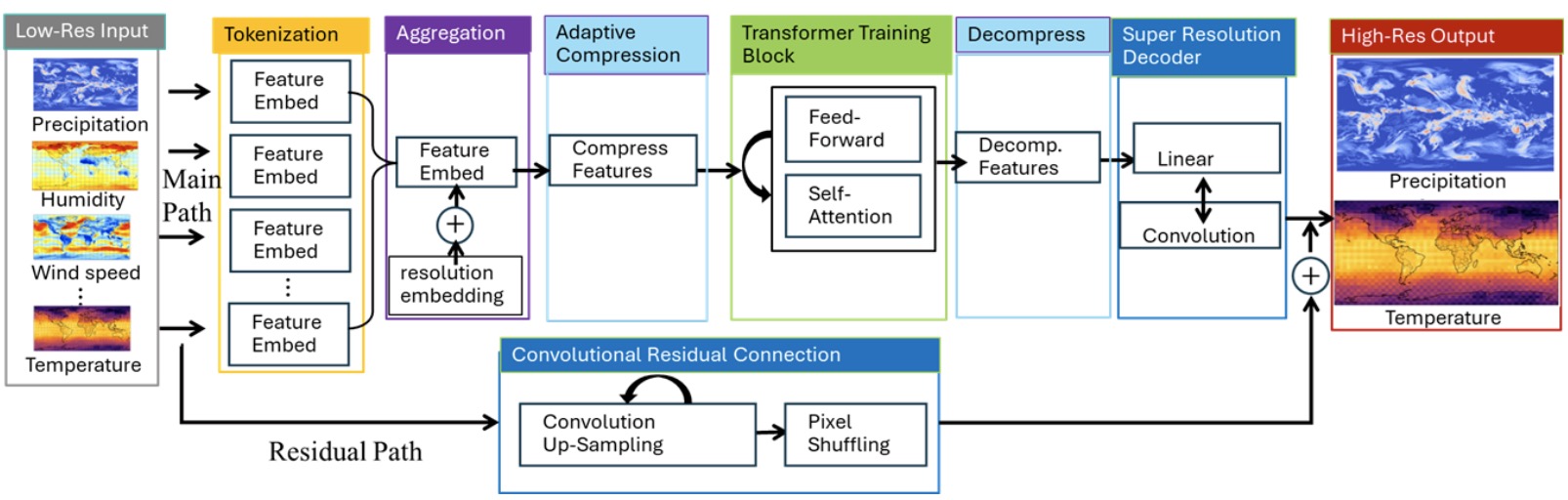
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling Xiao Wang, Jong-Youl Choi, Takuya Kurihaya, Isaac Lyngaas, Hong-Jun Yoon, Xi Xiao, David Pugmire, Ming Fan, Nasik M. Nafi, Aristeidis Tsaris, Ashwin M. Aji, Maliha Hossain, Mohamed Wahib, Dali Wang, Peter Thornton, Prasanna Balaprakash, Moetasim Ashfaq, Dan Lu SC, 2025 Best Paper Award, Gordon Bell Prize Finalist paper / code / AMD story An exascale vision transformer for high-resolution climate downscaling on Frontier, enabling accurate and efficient prediction of regional weather and climate extremes. |
|
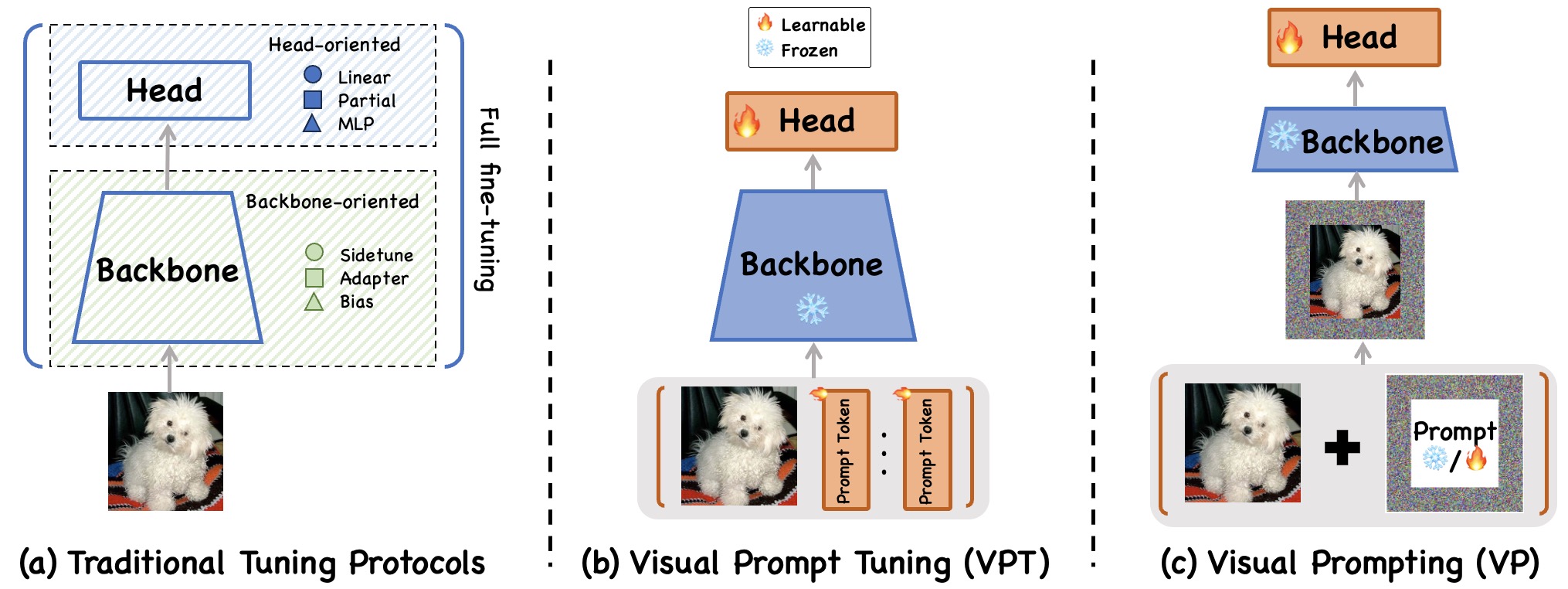
Prompt-based Adaptation in Large-scale Vision Models: A Survey Xi Xiao, Yunbei Zhang, Lin Zhao, Yiyang Liu, et al. TMLR, 2026 paper / resources A comprehensive taxonomy and survey of visual prompt tuning and prompting for large vision models, covering learnable, generative, and non-learnable prompts across diverse tasks. |
|
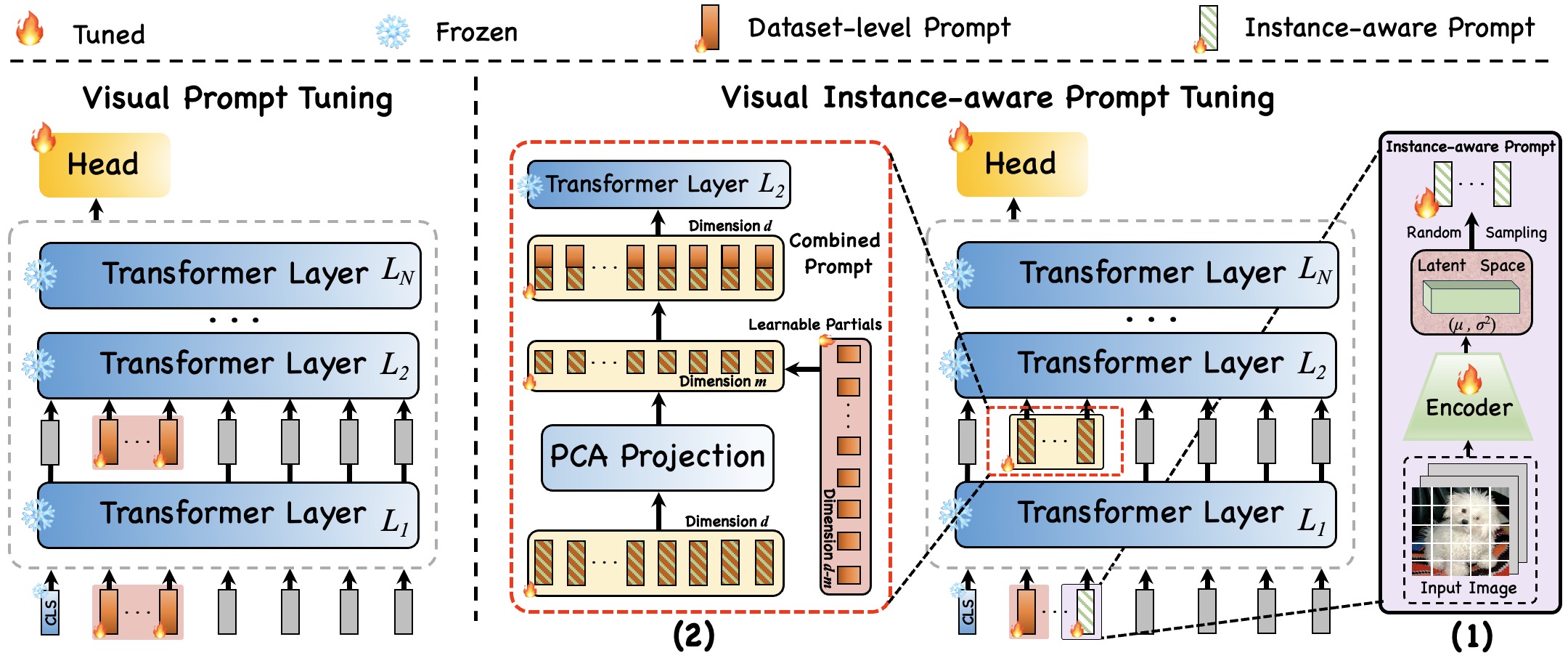
Visual Instance-aware Prompt Tuning Xi Xiao, Yunbei Zhang, Xingjian Li, Tianyang Wang, Xiao Wang, Yuxiang Wei, Jihun Hamm, Min Xu ACM MM, 2025 paper / code Instance-aware visual prompts that adapt to each image, mitigating overfitting and improving transferability of ViT-based classifiers under distribution shift. |

|
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization Hengjia Li*, Lifan Jiang*, Xi Xiao*, Tianyang Wang, Hongwei Yi, Boxi Wu, Deng Cai ICCV, 2025 (* equal contribution) project page / paper / code A hybrid preference optimization framework that jointly preserves identity and motion dynamics for personalized text-to-video generation. |

|
CAD-VAE: Leveraging Correlation-Aware Latents for Comprehensive Fair Disentanglement Chenrui Ma, Xi Xiao, Tianyang Wang, Xiao Wang, Yanning Shen AAAI, 2026 paper / code A correlation-aware latent space that jointly improves disentanglement and fairness in generative models through causal regularization. |
|
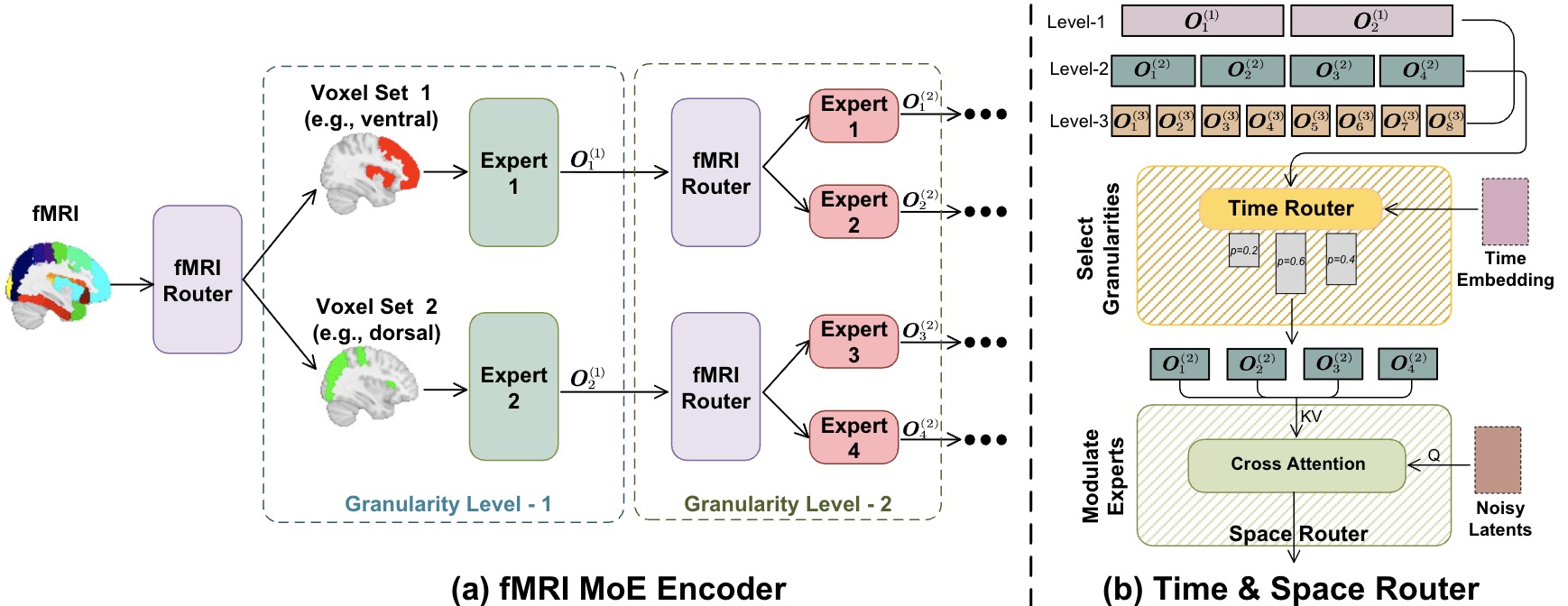
MoRE-Brain: Routed Mixture of Experts for Interpretable and Generalizable Cross-Subject fMRI Visual Decoding Yuxiang Wei, Yanteng Zhang, Xi Xiao, Tianyang Wang, Xiao Wang, Vince D. Calhoun NeurIPS, 2025 paper / code A routed mixture-of-experts architecture for diffusion-based fMRI-to-image reconstruction, achieving strong cross-subject generalization and interpretable brain–model alignment. |
|
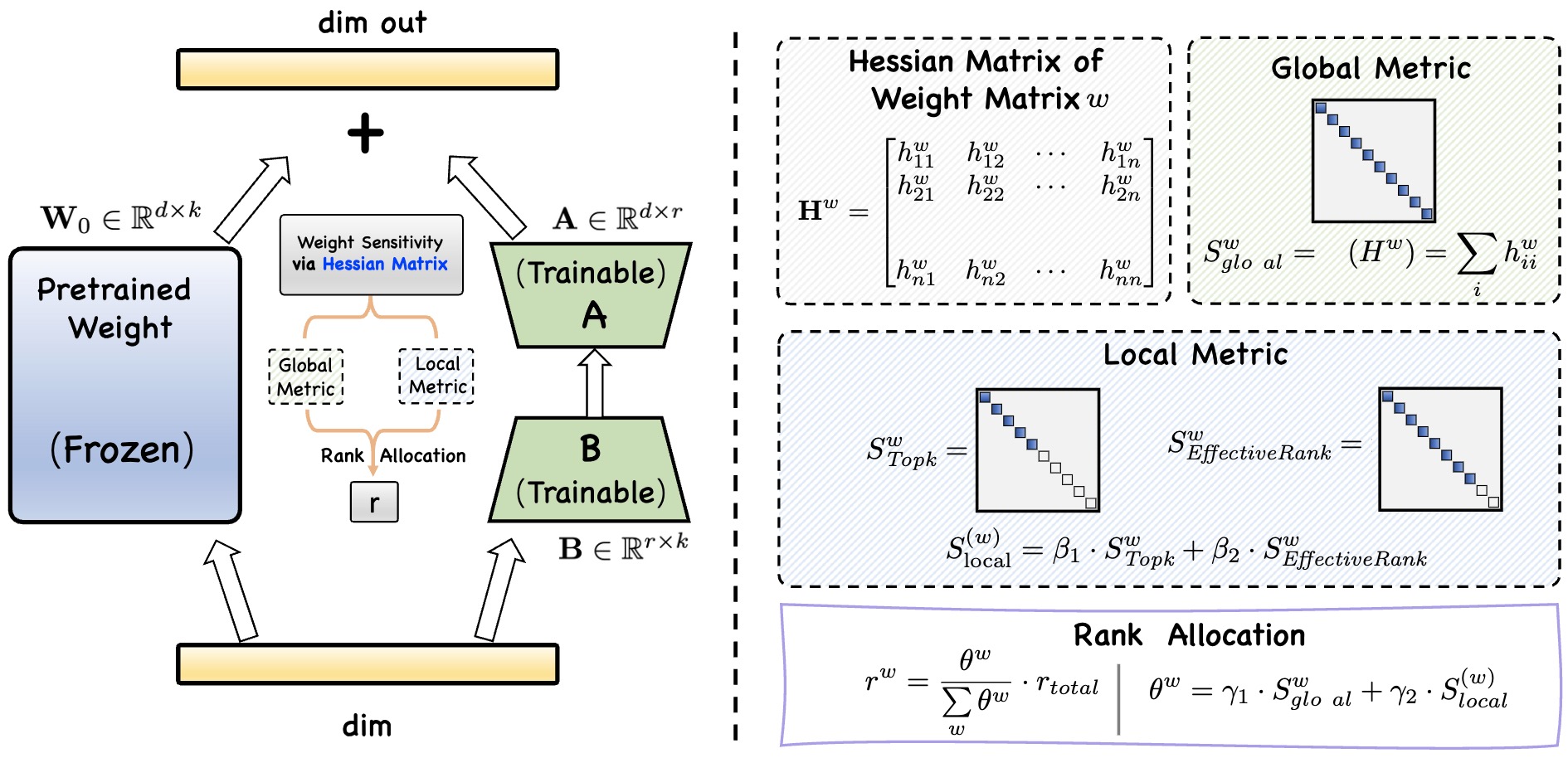
Sensitivity-LoRA : Low-Load Sensitivity-Based Fine-Tuning for Large Language Models Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, Hao Xu Findings of EMNLP, 2025 paper / code An efficient fine-tuning method that dynamically allocates ranks to weight matrices based on both their global and local sensitivities. It leverages the second-order derivatives (Hessian Matrix) of the loss function to effectively capture weight sensitivity, enabling optimal rank allocation with minimal computational overhead. |
|
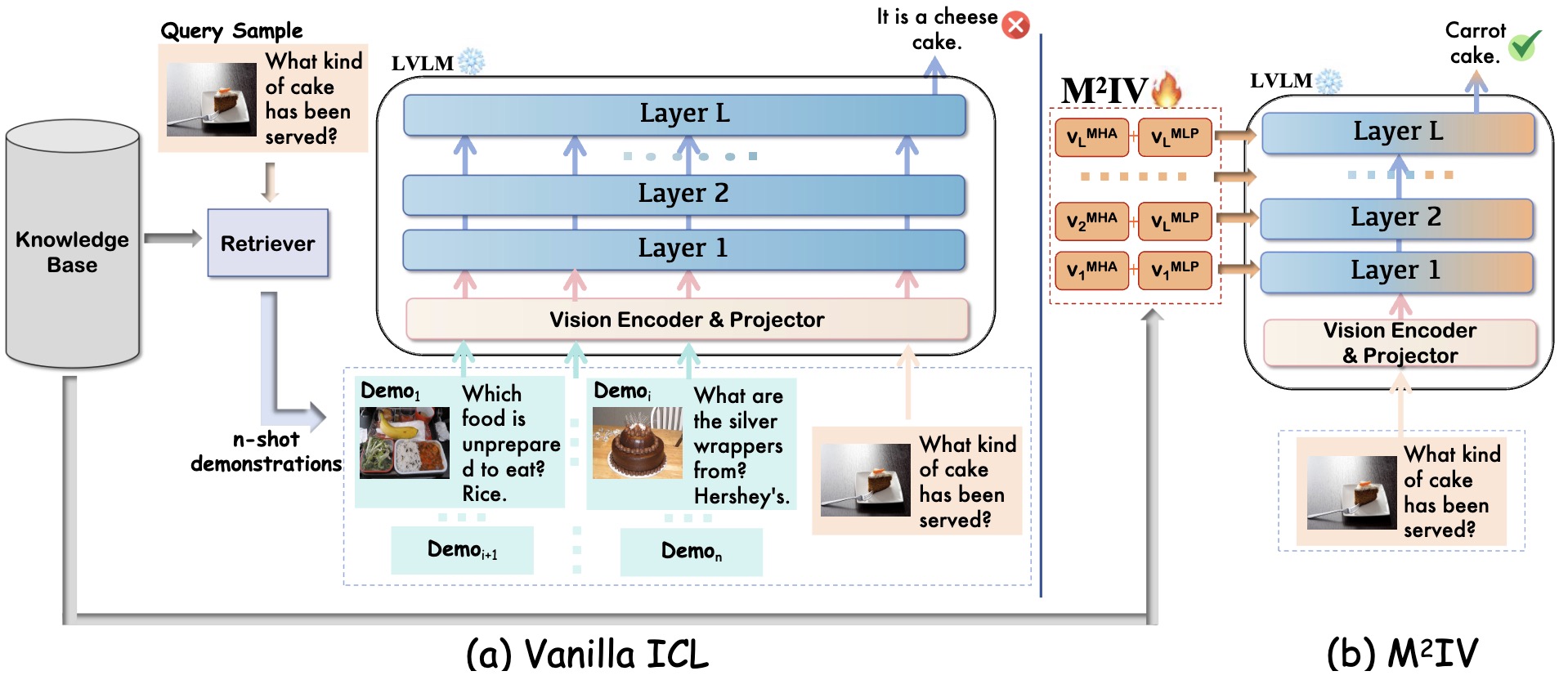
M²IV: Towards Efficient and Fine-grained Multimodal In-Context Learning via Representation Engineering Yanshu Li, Yi Cao, Hongyang He, Qisen Cheng, Xiang Fu, Xi Xiao, Tianyang Wang, Ruixiang Tang COLM, 2025 paper / code A novel representation engineering approach that replaces explicit token-level demonstrations with a set of learnable Multimodal In-context Vectors directly injected into the residual streams of LVLMs. |
Professional Experience
|
Awards & Honors
|
Miscellanea |
Talks & Media |
AMD story on ORBIT-2 and Frontier exascale climate modeling
More invited talks and interviews coming soon. |
Academic Service |
Reviewer for top-venue conferences and journals including NeurIPS, ICML, CVPR, AAAI, ACM MM, TMLR, IEEE TCSVT, npj Digital Medicine. |
|
Website adapted from Jon Barron's template. |